C'est le scénario classique dans le monde de l'IA générative : on monte un PoC (Proof of Concept) en un après-midi avec LangChain ou LlamaIndex, ça marche super bien sur trois documents PDF de test, et tout le monde est impressionné. Mais dès qu'on passe à l'échelle avec des milliers de fichiers, c'est la douche froide.
Pourquoi mon RAG ne fonctionne pas une fois en production ? Les utilisateurs se plaignent : mon RAG donne de mauvaises réponses, le recall est faible (il rate des infos évidentes), et les hallucinations pointent le bout de leur nez dès que la question se complexifie.
Si vous vous demandez comment améliorer un RAG existant sans tout réécrire ni changer nécessairement de LLM (comme GPT-4 ou Claude 3.5), vous êtes au bon endroit. Optimiser un RAG, ce n'est pas juste une question de prompt engineering, c'est avant tout une question d'architecture, d'ingénierie de la donnée et de pipeline de recherche.
Nous allons décortiquer ensemble les leviers concrets pour booster la performance RAG, de l'hybrid search au query rewriting, en passant par le parsing intelligent et l'évaluation rigoureuse.
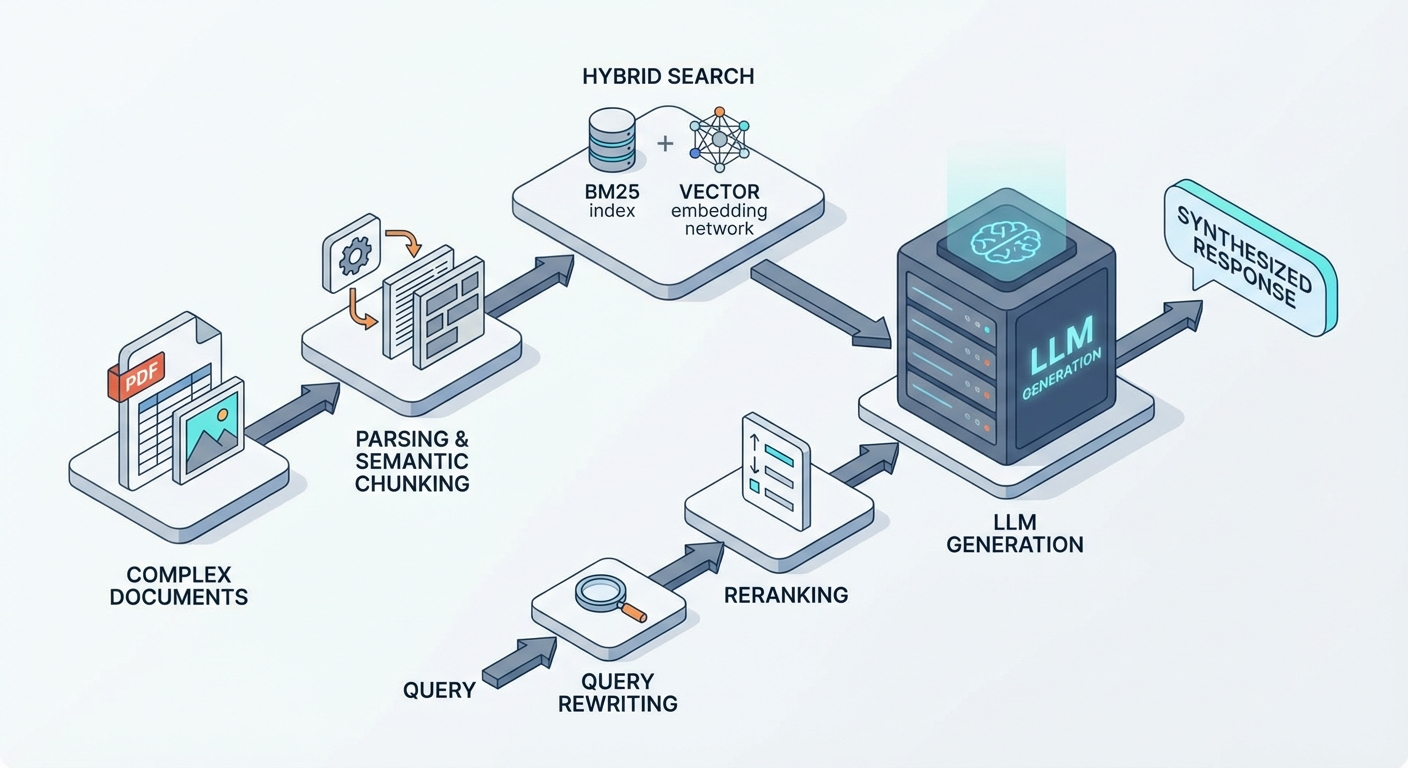
1. L'Hybrid Search : Ne misez pas tout sur la sémantique
Soyons clairs : la recherche vectorielle (semantic search) via des embeddings, c'est magique, mais ça n'est pas infaillible. Beaucoup de développeurs font l'erreur de jeter les anciennes méthodes. Or, je pense que dans un premier temps, le Hybrid Search combinant BM25 et recherche vectorielle est un choix architectural incontournable, surtout si vous bossez sur des cas d'usage précis comme le e-commerce, la documentation technique ou le juridique.
Pourquoi la sémantique seule échoue ?
La recherche vectorielle (Dense Retrieval) excelle pour capter le sens global, le contexte ("chaussures de sport pour courir"). Mais elle peut rater des correspondances exactes ou échouer sur du vocabulaire "hors domaine" (Out-of-Distribution). Si un utilisateur cherche une référence produit spécifique (ex: "SKU-12345"), un acronyme rare ou un nom propre, les embeddings peuvent noyer l'information dans un concept vectoriel trop vague.
La puissance du duo BM25 + Vecteurs
C'est là que l'approche hybride brille :
- BM25 (Keyword Search / Sparse Retrieval) : C'est une version améliorée du TF-IDF. Il se fiche du sens, il cherche les mots-clés exacts et leur fréquence. Si l'utilisateur tape "Erreur 504 Gateway", BM25 trouvera le document exact qui contient ce code.
- Recherche Vectorielle : Elle gère les synonymes et l'intention. Elle trouvera la réponse même si l'utilisateur demande "Pourquoi le serveur ne répond pas ?" sans citer le code d'erreur.
Pour optimiser un RAG en production, il ne suffit pas de faire les deux recherches en parallèle. Il faut fusionner les résultats intelligemment via un algorithme comme le RRF (Reciprocal Rank Fusion). Le RRF normalise les scores des deux méthodes pour remonter les documents qui sont pertinents à la fois sémantiquement et lexicalement. C'est souvent le "quick win" le plus efficace pour corriger un RAG faible recall.
2. Parsing de documents pour RAG : "Garbage In, Garbage Out"
L'autre pilier souvent négligé, c'est le parsing avant le chunking. On a tendance à penser que le LLM va se débrouiller et "nettoyer" le contexte, mais c'est faux. Si on lui donne de la bouillie, il sortira de la bouillie ou, pire, il hallucinera. Comment on extrait des informations d'un document proprement ?
Extraire uniquement le texte brut avec des méthodes classiques comme un script Python basique et pypdf ne suffit plus à tous les cas d'usage. C'est la cause numéro 1 des échecs sur les RAG documents PDF complexes. Les PDF sont des formats d'impression, pas des formats de données : ils n'ont souvent aucune notion de paragraphes, de titres ou de structure logique.
L'ère du "Visual RAG" et de l'OCR
Récemment, avec l'arrivée de modèles comme dots.ocr (de Hugging Face) ou les capacités multimodales de modèles type DeepSeek OCR, GPT-4o Vision ou Llama Vision, la problématique du parsing devient plus gérable, mais reste cruciale.
L'OCR pour RAG est devenu essentiel pour traiter :
- Les Tableaux : C'est la bête noire des RAG. Si vous aplatissez un tableau en texte brut ligne par ligne, vous perdez la relation verticale (colonne/valeur). Le LLM ne comprendra rien aux chiffres. Il faut convertir ces tableaux en Markdown ou HTML structuré pour conserver la sémantique spatiale.
- Les Images et graphiques : Les schémas techniques ou les graphiques financiers contiennent souvent la réponse. Il faut soit les décrire textuellement (captioning) via un modèle VLM, soit vectoriser l'image elle-même (embedding multimodal).
- Les mises en page complexes : Les doubles colonnes, les encadrés, les pieds de page (headers/footers) qui viennent polluer le texte au milieu d'une phrase.
Pour gérer un RAG tableaux et images, investissez du temps sur des parseurs "Layout-Aware" (conscients de la mise en page) type Unstructured, Docling, Azure Document Intelligence ou des solutions basées sur la vision. L'objectif est de transformer votre PDF en un format propre (idéalement du Markdown) avant même de penser à le découper.
3. Le Chunking RAG : Du découpage bête au Semantic Chunking
Le chunking, c'est l'art de découper votre texte en morceaux digestes pour le modèle d'embedding et le LLM. Souvent, par facilité, on se contente d'un découpage par taille fixe (ex: 500 caractères avec un overlap de 50). Pour atteindre de hautes performances, on néglige souvent cette étape, alors que chaque document a besoin d'un chunking sur mesure.
Le problème du découpage fixe, c'est qu'il est aveugle. Couper une phrase en plein milieu ou, pire, séparer une question de sa réponse dans deux chunks différents, détruit le contexte. Le modèle d'embedding va générer deux vecteurs incomplets, et la recherche échouera.
L'approche du Semantic Chunking
C'est là que le Semantic Chunking entre en jeu. Au lieu de couper au kilomètre, on analyse le sens du texte. On utilise un petit modèle d'embedding pour calculer la similarité entre des phrases consécutives.
- Tant que le sujet reste le même (similarité élevée), on continue de remplir le chunk.
- Dès qu'il y a une rupture de sujet (la similarité chute), on ferme le chunk et on en ouvre un nouveau.
Cela garantit que chaque morceau contient une idée complète et cohérente, ce qui améliore drastiquement la qualité du retrieval.
Lien utile : A Visual Exploration of Semantic Text Chunking
Astuce d'expert : Le Parent Document Retriever
Une autre technique puissante consiste à découpler ce qu'on cherche de ce qu'on donne au LLM. Vous pouvez indexer des petits chunks (très précis pour la recherche vectorielle) mais lier ces petits chunks à un "Chunk Parent" plus large. Quand le petit chunk matche, on envoie le gros chunk parent au LLM. Cela offre le meilleur des deux mondes : la précision de la recherche et la richesse du contexte pour la génération.
4. Query Rewriting RAG : Reformuler pour mieux trouver
Un autre point important qui peut bloquer, c'est la requête elle-même. Dans le RAG de base, la base vectorielle est requêtée avec la question brute de l'utilisateur. Sauf que le problème avec ça, c'est que parfois la réponse ne contient aucun élément lexical de la question.
C'est le problème de la "distance sémantique" ou du désalignement.
- Question utilisateur : "Je n'arrive pas à me connecter, ça tourne dans le vide."
- Document réponse : "Procédure de résolution des timeouts sur le serveur d'authentification OAuth2."
Trouver une réponse dans la base vectorielle en cherchant avec la question utilisateur n'a pas de sens si le champ sémantique diffère trop. C'est là qu'intervient le Query Rewriting RAG. L'idée est d'utiliser un LLM intermédiaire pour "traduire" l'intention de l'utilisateur en une requête optimisée pour la base de données.
Voici quelques techniques phares :
- Multi-Query Expansion : Le LLM génère 3 ou 4 variantes de la question sous différents angles ou avec des synonymes techniques. On exécute toutes ces recherches et on dédoublonne les résultats. Cela permet de ratisser plus large.
- HyDE (Hypothetical Document Embeddings) : C'est la technique dont tu cherchais le nom ! On demande au LLM de halluciner une réponse idéale (même fausse factuellement), puis on utilise cette fausse réponse pour chercher dans la base. On cherche alors "réponse contre réponse" (document contre document) plutôt que "question contre réponse". La proximité sémantique est souvent bien meilleure.
- Query Decomposition : Pour les questions complexes ("Quelle est la différence de CA entre 2022 et 2023 ?"), on divise la demande en sous-questions simples ("CA 2022 ?", "CA 2023 ?") à résoudre séquentiellement.
5. Le Reranking RAG : La finition de précision
D'autres techniques peuvent être utilisées comme le Reranking RAG (ou réordonnancement), mais je suis d'accord : pas avant d'avoir bien exploré dans l'ordre l'hybrid search, le meilleur parsing et le chunking. C'est la cerise sur le gâteau, pas la base du gâteau.
Bi-Encoder vs Cross-Encoder
Votre base vectorielle utilise des "Bi-Encoders" : c'est très rapide car les vecteurs des documents sont pré-calculés. Mais c'est une mesure de similarité approximative (produit scalaire ou cosinus).
Le Reranker (un modèle Cross-Encoder type Cohere Rerank ou bge-reranker-v2-m3) fonctionne différemment. Il prend la question et le document ensemble et les analyse en profondeur pour sortir un score de pertinence.
Le process optimisé ressemble à ça :
- Retrieval : On récupère large (ex: les 50 documents les plus proches) via la base vectorielle (rapide).
- Reranking : Le Cross-Encoder relit ces 50 documents et les reclasse intelligemment.
- Top-K : On ne garde que les 5 meilleurs pour le LLM.
C'est coûteux en temps de calcul (latence), mais c'est l'arme fatale pour améliorer la précision d'un RAG et s'assurer que le document contenant la réponse exacte remonte de la 15ème à la 1ère place.
Conclusion : Audit et Évaluation RAG
Pour améliorer un RAG sans changer de modèle, il n'y a pas de magie, seulement de la méthode. Évidemment, avant d'explorer ces éléments techniques, ce qu'il faut faire c'est une analyse des réponses, comprendre les erreurs et essayer d'apporter des solutions pragmatiques. Tensoria vous accompagne dans cette démarche via notre expertise d'agence IA à Toulouse.
Il est impératif de mettre en place un pipeline d'évaluation RAG et d'audit RAG. Ne vous fiez pas à votre intuition. Nous proposons des services d'audit IA spécifiques pour les systèmes en production. Ces outils permettent de créer des métriques objectives :
- Context Precision : Est-ce que mes chunks récupérés sont utiles ?
- Context Recall : Est-ce que j'ai récupéré toute l'information nécessaire ?
- Faithfulness : Est-ce que le LLM respecte le contexte ou invente-t-il ?
La clé du succès d'un RAG en production, c'est l'itération. Pour les entreprises souhaitant automatiser leur relation client, cela peut déboucher sur un chatbot entreprise de haute performance.
Passer au concret
Planifiez un échange pour optimiser votre système RAG.
Questions fréquentes sur l'optimisation RAG
Pourquoi mon RAG fonctionne bien en démo mais donne de mauvaises réponses en production ?
C'est le problème classique du passage à l'échelle. En démo, vous testez sur 3 documents PDF simples, mais en production avec des milliers de fichiers, plusieurs problèmes apparaissent : le recall est faible (le système rate des informations évidentes), les hallucinations augmentent, et la recherche vectorielle seule échoue sur des correspondances exactes (références produits, acronymes, noms propres). Les causes principales sont : un parsing insuffisant des documents complexes, un chunking fixe qui détruit le contexte, et l'absence d'hybrid search combinant recherche vectorielle et BM25.
Qu'est-ce que l'hybrid search et pourquoi est-ce essentiel pour optimiser un RAG ?
L'hybrid search combine deux méthodes de recherche : BM25 (keyword search) qui cherche les mots-clés exacts et leur fréquence, et la recherche vectorielle (semantic search) qui gère les synonymes et l'intention. La recherche vectorielle seule peut rater des correspondances exactes (ex: "SKU-12345", "Erreur 504 Gateway") car elle noie l'information dans un concept vectoriel trop vague. L'hybrid search fusionne intelligemment les résultats via le RRF (Reciprocal Rank Fusion) pour remonter les documents pertinents à la fois sémantiquement et lexicalement. C'est souvent le "quick win" le plus efficace pour corriger un RAG avec faible recall.
Comment améliorer le parsing de documents PDF complexes pour un RAG ?
Le parsing est crucial car "Garbage In, Garbage Out". Extraire uniquement le texte brut avec pypdf ne suffit plus. Pour les tableaux, il faut les convertir en Markdown ou HTML structuré pour conserver la relation colonne/valeur. Pour les images et graphiques, utilisez un modèle VLM pour le captioning ou un embedding multimodal. Pour les mises en page complexes (doubles colonnes, encadrés, headers/footers), investissez dans des parseurs "Layout-Aware" comme Unstructured, Docling, Azure Document Intelligence ou des solutions basées sur la vision (OCR avec modèles type dots.ocr, DeepSeek OCR, GPT-4o Vision). L'objectif est de transformer votre PDF en Markdown propre avant le chunking.
Qu'est-ce que le semantic chunking et en quoi améliore-t-il les performances RAG ?
Le semantic chunking remplace le découpage fixe (ex: 500 caractères) par une analyse du sens du texte. Au lieu de couper au kilomètre, on utilise un modèle d'embedding pour calculer la similarité entre phrases consécutives : tant que le sujet reste le même (similarité élevée), on continue de remplir le chunk ; dès qu'il y a une rupture de sujet (similarité chute), on ferme le chunk. Cela garantit que chaque morceau contient une idée complète et cohérente, évitant de couper une phrase en plein milieu ou de séparer une question de sa réponse. Le Parent Document Retriever est une variante puissante : indexer de petits chunks précis pour la recherche, mais lier ces chunks à un "chunk parent" plus large pour le LLM, offrant précision de recherche et richesse de contexte.
Comment fonctionne le query rewriting pour améliorer un RAG ?
Le query rewriting résout le problème de "distance sémantique" : parfois la réponse ne contient aucun élément lexical de la question. Par exemple, la question "Je n'arrive pas à me connecter, ça tourne dans le vide" ne matche pas lexicalement avec "Procédure de résolution des timeouts sur le serveur d'authentification OAuth2". Le query rewriting utilise un LLM intermédiaire pour "traduire" l'intention en requête optimisée. Techniques principales : Multi-Query Expansion (générer 3-4 variantes de la question), HyDE (Hypothetical Document Embeddings) (demander au LLM d'halluciner une réponse idéale, puis chercher "réponse contre réponse"), et Query Decomposition (diviser les questions complexes en sous-questions simples).
Qu'est-ce que le reranking RAG et quand l'utiliser ?
Le reranking RAG (réordonnancement) est une technique de finition de précision, à utiliser après avoir optimisé l'hybrid search, le parsing et le chunking. Votre base vectorielle utilise des "Bi-Encoders" (rapides mais approximatifs). Le reranker est un modèle Cross-Encoder (type Cohere Rerank ou bge-reranker-v2-m3) qui analyse la question et le document ensemble pour un score de pertinence précis. Le processus : (1) Retrieval : récupérer large (ex: 50 documents) via la base vectorielle rapide ; (2) Reranking : le Cross-Encoder reclasse ces 50 documents ; (3) Top-K : garder les 5 meilleurs pour le LLM. C'est coûteux en latence mais efficace pour améliorer la précision et faire remonter le document exact de la 15ème à la 1ère place.
Comment évaluer et auditer un système RAG en production ?
Il est impératif de mettre en place un pipeline d'évaluation RAG et d'audit RAG avec des métriques objectives, pas seulement l'intuition. Utilisez des frameworks comme RAGAS, TruLens ou DeepEval pour mesurer : Context Precision (mes chunks récupérés sont-ils utiles ?), Context Recall (ai-je récupéré toute l'information nécessaire ?), et Faithfulness (le LLM respecte-t-il le contexte ou invente-t-il ?). La clé du succès est l'itération : Expérimenter (changer la taille des chunks), Évaluer (score RAGAS), Corriger et recommencer jusqu'à atteindre la meilleure performance. Avant d'explorer les techniques techniques, analysez d'abord les réponses, comprenez les erreurs et apportez des solutions pragmatiques.
Peut-on améliorer un RAG sans changer de LLM (GPT-4, Claude 3.5) ?
Oui, absolument. Optimiser un RAG ne se limite pas au prompt engineering ou au changement de LLM. C'est avant tout une question d'architecture, d'ingénierie de la donnée et de pipeline de recherche. Les leviers principaux sont : (1) Hybrid search (BM25 + recherche vectorielle) pour améliorer le recall ; (2) Parsing intelligent des documents complexes (tableaux, images, mises en page) ; (3) Semantic chunking au lieu du découpage fixe ; (4) Query rewriting pour réduire la distance sémantique ; (5) Reranking pour la finition de précision. Ces optimisations peuvent drastiquement améliorer les performances sans toucher au LLM de génération.
Dans quel ordre optimiser les différentes composantes d'un RAG ?
L'ordre d'optimisation recommandé est : (1) Hybrid search en premier (quick win le plus efficace pour corriger le faible recall) ; (2) Parsing intelligent des documents (résout les problèmes de "Garbage In, Garbage Out") ; (3) Semantic chunking (améliore la qualité du retrieval en préservant le contexte) ; (4) Query rewriting (réduit la distance sémantique entre questions et réponses) ; (5) Reranking en dernier (finition de précision, mais coûteux en latence). Le reranking est la "cerise sur le gâteau", pas la base. Commencez par les fondamentaux (hybrid search, parsing, chunking) avant d'ajouter des couches de complexité.
Pour aller plus loin
- RAG vs Chatbot Simple : quand utiliser quoi ? : différences et critères de choix.
- Comprendre le RAG appliqué aux données internes : architecture, limites et bonnes pratiques.
- 3 Cas d'Usage du RAG en Entreprise : e-commerce, industrie et gestion interne.
- Diagnostic IA interne : cartographier vos données et prioriser les cas d'usage.
- Audit IA : sécuriser vos investissements et votre gouvernance data.
- Rédaction de mémoires techniques : comment le RAG réduit le temps de production documentaire.