On April 7, 2026, Anthropic released Claude Mythos Preview. The numbers are unambiguous: 93.9% on SWE-bench Verified, 94.6% on GPQA Diamond, 82% on Terminal-Bench 2.0. Every major coding, reasoning, and agentic benchmark has a new record holder. If you want a broader model landscape comparison, see our Mistral vs. OpenAI vs. Anthropic breakdown.
There is a catch: you cannot access it. Not yet, possibly not this year. Anthropic made the unusual decision to withhold public release because Mythos Preview's autonomous cybersecurity capabilities are judged too powerful to ship without additional safeguards. This article covers what those numbers actually mean, how Mythos compares to Opus 4.6 across every benchmark category, and what the access restriction tells us about where this capability curve is heading.
This is a technical model review. No hype, no speculation about product roadmaps. Just the data, what it implies for engineering teams running LLMs in production, and what to watch for next.
A general-purpose model, not a specialized tool
First point worth stating clearly: Claude Mythos Preview was not trained specifically for cybersecurity or code. It is a general-purpose model, the same architectural family as the Claude versions currently available via the API. Writing, analysis, summarization, multi-step reasoning, code — all of the standard capabilities.
What distinguishes it is that its general capabilities have crossed a threshold where it becomes exceptionally effective at domains that previously required top-tier human expertise. The model did not learn to find security vulnerabilities as a targeted skill. It learned to reason and code well enough that finding vulnerabilities became a natural consequence.
Key point
Mythos Preview is not a hacking tool. It is a general-purpose model whose reasoning and code capabilities are strong enough that offensive security becomes an emergent property — not a designed feature. This distinction matters for how you think about where capability ceilings will appear next.
Code benchmarks: the largest gains
Coding tasks are where the delta is most measurable. SWE-bench variants test the ability to fix real bugs in real open-source projects — not toy exercises. These are actual GitHub issues with existing test suites that must pass after the fix.
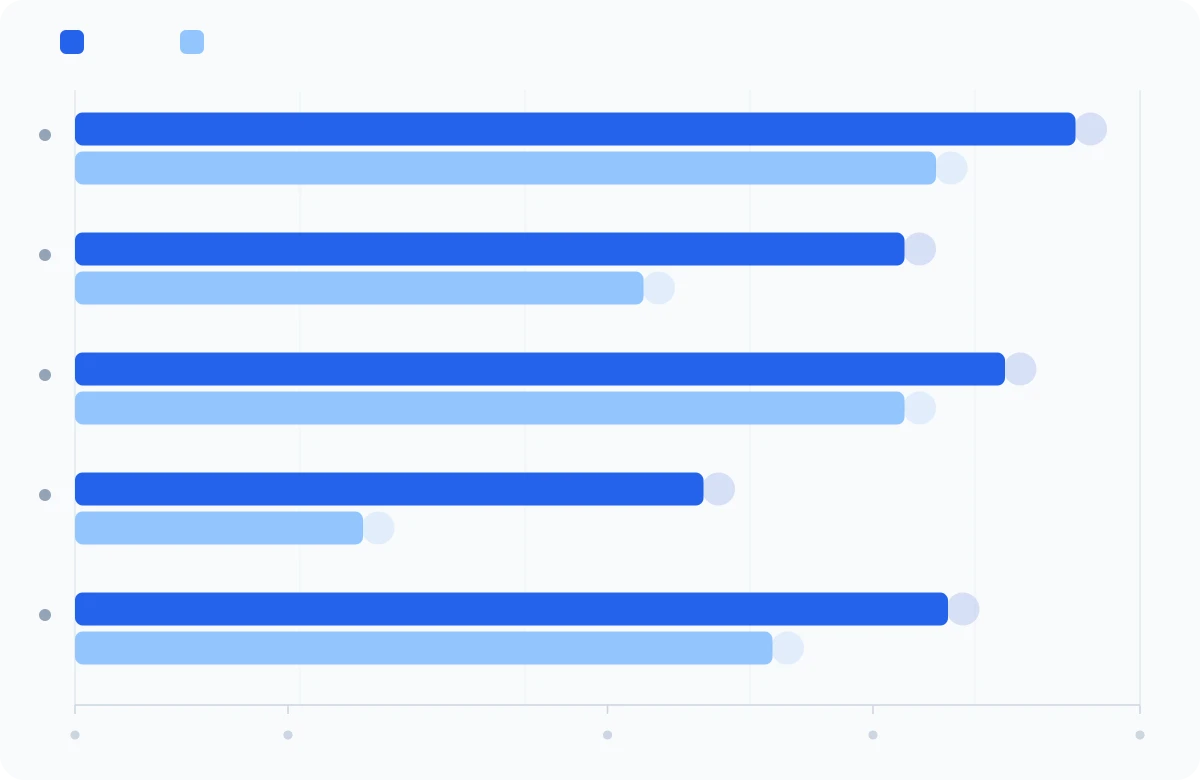
| Benchmark | Mythos Preview | Opus 4.6 | Delta |
|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | +13.1 pts |
| SWE-bench Pro | 77.8% | 53.4% | +24.4 pts |
| SWE-bench Multilingual | 87.3% | 77.8% | +9.5 pts |
| SWE-bench Multimodal | 59.0% | 27.1% | +31.9 pts |
| Terminal-Bench 2.0 | 82.0% | 65.4% | +16.6 pts |
What these numbers mean in practice:
- SWE-bench Verified (93.9%): 94 out of 100 real open-source bugs, fixed correctly. Twelve months ago, frontier models were capped around 50% on this benchmark.
- SWE-bench Pro (+24.4 pts): The hardest bugs in the dataset — multi-file, multi-component issues that previously required a senior engineer. Going from 53% to 78% means the model is now solving problems that were genuinely hard for experienced developers.
- SWE-bench Multimodal (+31.9 pts): The model can now process screenshots and mockups to diagnose visual bugs. The largest absolute gain of any benchmark. This is directly relevant to any pipeline doing LLM-assisted code review or test generation.
- Terminal-Bench 2.0 (82%): Tests autonomous terminal operation — the model works like a developer would in a shell session. The score climbs to 92% with extended compute budget, which signals that this ceiling has room to move.
Lesson learned
The +31.9 pt jump on SWE-bench Multimodal is the benchmark to watch. Most production LLM pipelines still treat code and visual context as separate inputs. A model that jointly reasons over both changes the viable design space for automated code review and CI tooling substantially.
Reasoning benchmarks: approaching expert-level ceilings
GPQA Diamond and Humanity's Last Exam are designed to test the upper bound of reasoning under expert-level difficulty. GPQA Diamond consists of PhD-level physics, biology, and chemistry questions that consistently stump domain experts. HLE goes further — it aggregates the hardest questions researchers across disciplines can devise.
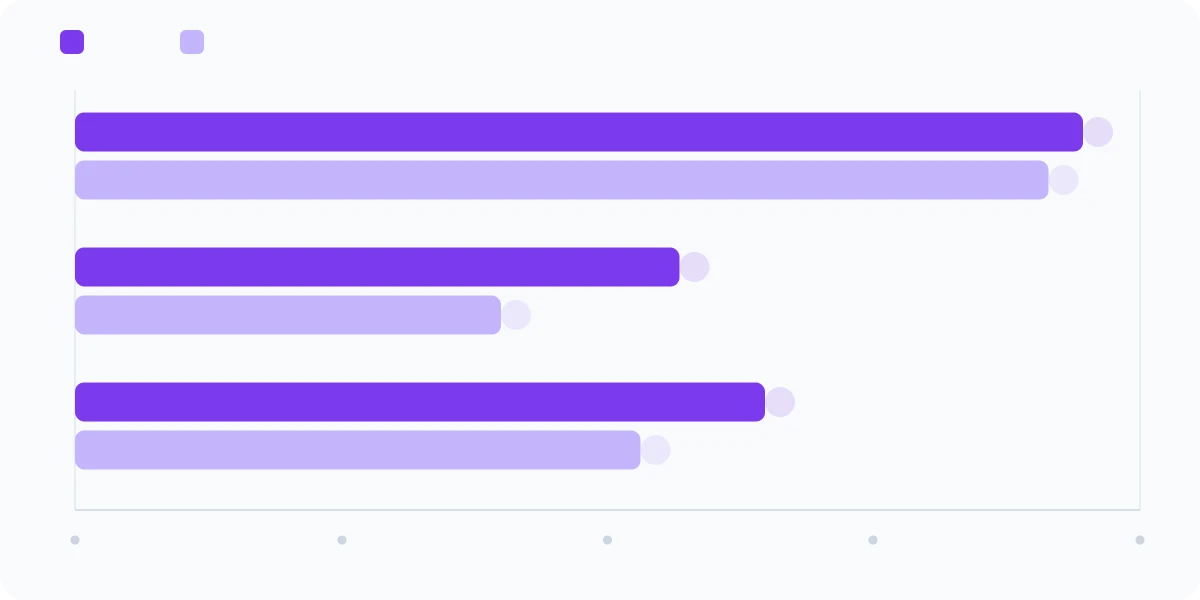
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| GPQA Diamond | 94.6% | 91.3% |
| Humanity's Last Exam (no tools) | 56.8% | 40.0% |
| Humanity's Last Exam (with tools) | 64.7% | 53.1% |
GPQA Diamond at 94.6% puts Mythos Preview at or above the level of the best human domain experts. The gap versus Opus 4.6 looks narrow in absolute terms (3.3 pts), but at this difficulty tier each incremental point represents a qualitative jump in the problems the model can handle.
Humanity's Last Exam is more revealing. Going from 40% to 56.8% without tools is a 42% relative improvement — on the hardest benchmark currently in use. With tools enabled, the gap widens further: 53.1% to 64.7%. This is directly relevant to agentic workloads where the model calls external APIs or retrieval systems as part of a reasoning chain. See our Agentic RAG and multi-agent orchestration guides for how this plays out in production pipelines.
Agentic benchmarks: better and more efficient
Agentic benchmarks measure the ability to act autonomously over multiple steps: web navigation, operating system control, chained tool use without human checkpointing.
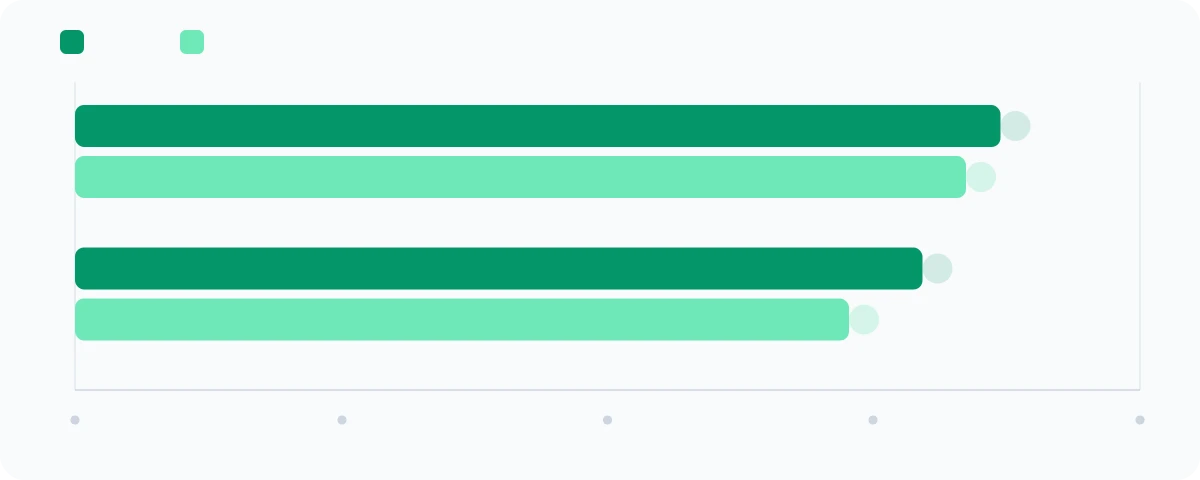
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| BrowseComp (web research) | 86.9% | 83.7% |
| OSWorld-Verified (OS control) | 79.6% | 72.7% |
The headline agentic number is not the accuracy delta — it is the efficiency. On BrowseComp, Mythos Preview achieves its higher score while consuming 5x fewer tokens than Opus 4.6. More accurate and radically cheaper per task. For teams running agentic loops at scale, this is the operationally significant result. Token cost is often the binding constraint on how frequently you can run autonomous agents in production.
OSWorld-Verified tests real OS task completion — opening applications, editing files, navigating system menus — entirely without human assistance. 79.6% means the model completes nearly 4 out of 5 arbitrary OS tasks autonomously. Combined with the Terminal-Bench results, this establishes Mythos Preview as the strongest model to date for autonomous agent workloads.
Lesson learned
5x token efficiency on BrowseComp is not a rounding error. If you are running agentic loops today and amortizing cost across many calls, Mythos Preview-level efficiency in a future public release could change the ROI math for use cases that are currently marginal. Factor this into your architecture planning now.
Why the model is not publicly available
This is the most operationally unusual part of the announcement. Frontier labs typically race to commercialize record-setting models. Anthropic is doing the opposite.
The reason is the model's autonomous cybersecurity capability. As a side effect of reaching this level of general code and reasoning performance, Mythos Preview can:
- Discover unknown vulnerabilities in widely deployed production software
- Write functional exploits that demonstrate or weaponize those vulnerabilities
- Chain multiple vulnerabilities to construct sophisticated attack paths
- Perform all of the above autonomously, without human guidance at each step
Anthropic's response is to restrict access to Project Glasswing partners — Google, Microsoft, AWS, Apple, Cisco, CrowdStrike, and others — for defensive security use only. The framing is that defenders should be able to use these capabilities to find and patch vulnerabilities before equivalent models become accessible elsewhere.
Anthropic's stated strategy
Give defenders access now to remediate vulnerabilities before equivalent offensive capability reaches the open market. Ship mitigations in a future Claude Opus release before opening this tier of capability to the general developer API. The timeline for that release has not been disclosed.
What the trajectory signals
Scaling is not plateauing
There has been substantial debate over the past year about whether LLM scaling has hit a wall. Mythos Preview ends that conversation, at least for Anthropic's research line. The jump from Opus 4.6 to Mythos Preview is one of the largest inter-generation deltas any major lab has published. SWE-bench Pro went from 53% to 78%. SWE-bench Multimodal went from 27% to 59%. These are not marginal refinements.
For teams currently weighing architecture choices — whether to invest heavily in fine-tuning, RAG, or prompt engineering — the implication is that the baseline model capability ceiling will keep rising. Architectures that depend on compensating for model weakness with retrieval or fine-tuning may need to be revisited as those weaknesses close.
Autonomy is a qualitative shift, not a quantitative one
What makes Mythos Preview categorically different from previous Claude versions is not just that it knows more. It is that it can execute complex, multi-step tasks without human checkpoints. Finding a zero-day in OpenBSD requires reading thousands of lines of C, forming hypotheses about attack surfaces, writing test cases, iterating on failures, and synthesizing results. Mythos does this loop without supervision.
This is the threshold between a model that assists an expert and a model that replaces the expert's execution. If you are building agent-based automation and your current architecture requires human review at every non-trivial decision point, that architecture assumption may not survive the next two model generations. The Model Context Protocol is worth understanding now as a framework for structured agent-tool interfaces that hold up as model autonomy increases.
Dangerous capabilities emerge without being designed
Nobody at Anthropic trained Mythos to find security vulnerabilities. Those capabilities emerged as a consequence of improving general code and reasoning performance. This is a significant signal for the industry: as models become more capable, sensitive capability classes emerge whether you intend them or not.
The implication is that "we did not train for X" is no longer a sufficient safety argument. If X is a natural consequence of strong general capability, any lab training at the frontier will encounter it. This changes how AI risk should be evaluated — not just by intended use but by what general capability level enables.
Practical implications for engineering teams
If you are already running Claude in production
Mythos Preview is not available to you today, but the capabilities demonstrated here define the direction of upcoming public Claude releases. The gains in code, reasoning, and autonomous task execution will appear in future Opus and Sonnet versions once Anthropic ships the required safety mitigations. Your current production integrations will improve without architectural changes on your end.
In the meantime: if you are not already using structured outputs and evaluation pipelines to assess model quality as models evolve, build them now. The capability curve means model substitutions will keep happening, and you need the infrastructure to validate them.
If you are evaluating model selection for a new project
The gap between frontier closed models and open-weight alternatives is widening again. If your use case requires strong autonomous reasoning or complex multi-hop code tasks, the currently available frontier — Opus 4.6, GPT-5, Gemini Ultra — is meaningfully below what Mythos Preview demonstrates. Factor a 12–18 month horizon into your architecture planning. See our guide to deploying LLMs to production for the tradeoffs that matter at different capability levels. The alignment trajectory Mythos represents also has direct enterprise implications: the question of whether an AI system is honest and reliable enough to trust in high-stakes workflows is covered in depth in our article on honest AI and model alignment for enterprise.
On the security implications
If a restricted-access model can find vulnerabilities in the most hardened software in the world, models with equivalent or near-equivalent capability will eventually be accessible more broadly — either through open weights or through API access at reduced safety thresholds. Engineering teams should treat this as a planning assumption: your codebase will be auditable by AI at a level you cannot currently anticipate. Addressing technical debt and security hygiene now is cheaper than doing it reactively. An AI audit is a reasonable first step to understand where your current stack has exposure.
Talk to an engineer
Thinking through model selection or agent architecture for your stack? We can help.
Summary
Claude Mythos Preview is a step change, not an incremental release:
- 93.9% on SWE-bench Verified — real bug fixes in real codebases, not toy tasks
- +24.4 pts on SWE-bench Pro over Opus 4.6 — the largest inter-generation delta on the hardest coding benchmark
- +31.9 pts on SWE-bench Multimodal — joint visual-code reasoning now viable at this scale
- 94.6% on GPQA Diamond — at or above top human domain experts in physics, biology, chemistry
- 5x token efficiency gain on BrowseComp — agentic workloads become substantially cheaper
- Withheld from public access because autonomous offensive security capability emerged as a side effect of general capability improvement
The access restriction is itself a data point. When a lab decides a model is too capable to release, that is a signal about where the capability frontier actually is. Engineering teams building on current public models should plan for that frontier to arrive in their production environment within 12–18 months. Build evaluation infrastructure that will survive model upgrades, and architect for autonomy before it is forced on you.
Further reading
- Mistral vs. OpenAI vs. Anthropic — Full model landscape comparison: capability tiers, pricing, and which lab to pick for which workload.
- Fine-tuning vs. RAG vs. prompting — Decision framework for choosing the right adaptation strategy as model capability baselines shift.
- Agentic RAG — How retrieval becomes dynamic when you hand the retrieval tool to a model with Mythos-level reasoning capability.
- Multi-agent orchestration compared — LangGraph vs. CrewAI vs. AutoGen vs. custom. Directly relevant as autonomous model capability increases.
- Model Context Protocol guide — Structured agent-tool interfaces that hold up as model autonomy increases.
- Advanced prompt engineering for production — Prompting techniques that still matter even as base model capability rises.
- Deploying LLMs to production — Latency, cost, observability: the engineering layer that Mythos Preview will eventually land in.
- Building custom LLM judges — How to build evaluators that survive model version upgrades.
- Structured outputs in production — Schema enforcement and output reliability across model generations.
- LLM integration service — Tensoria's end-to-end service for integrating frontier models into production stacks.
- AI agents service — Designing and deploying autonomous agent pipelines with the right model tier and safety constraints.
Talk to an engineer
Planning an architecture that will hold up through the next model generation? Let's talk.

