Someone will pitch you RAG for every conversational AI problem. Someone else will tell you a simple chatbot is always enough. Both are wrong. The choice between a rule-based chatbot and Retrieval-Augmented Generation is an engineering decision with concrete criteria — not a trend to follow.
A simple chatbot maps inputs to pre-written outputs via rules, keywords, or a decision tree. Fast to ship, cheap to run, bounded by what you anticipated. RAG retrieves relevant passages from your document corpus at query time and grounds the LLM response in those sources. More powerful, more complex, higher operating cost, and only worth the investment when the use case actually demands it.
This article gives you the decision criteria, the tradeoffs, and the hybrid patterns. The goal is to help you pick the right architecture on day one, before you've sunk six weeks into the wrong one.
1. The core difference
A simple chatbot operates on pre-authored content. The system matches a user input to a scenario you designed — whether through an intent classifier, keyword matching, or a literal decision tree. It does not "understand" the question; it routes it. This is a feature, not a limitation: the output is fully predictable and every response is pre-approved. The ceiling is also the floor.
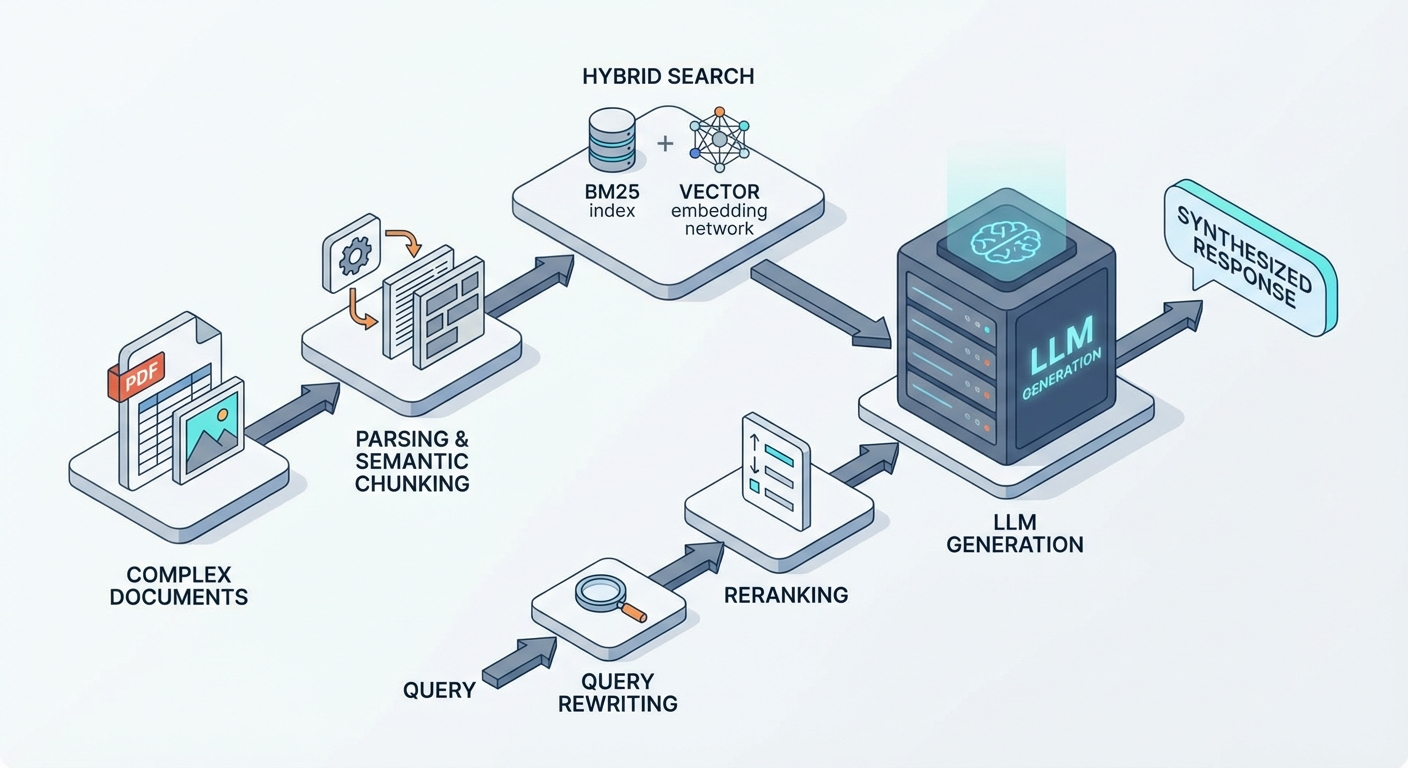
RAG, as defined in the original Lewis et al. paper and summarized in AWS's reference guide, pairs a retriever (typically dense vector search over an embedded document corpus) with a generator (an LLM that receives retrieved context as part of its prompt). The LLM answers from retrieved evidence rather than from parametric knowledge alone. The output is dynamic and grounded in your data — but it requires an ingestion pipeline, chunking decisions, embedding infrastructure, a vector store, and ongoing evaluation. For a full technical walkthrough, see our RAG primer.

2. Side-by-side comparison
| Criterion | Simple Chatbot | RAG |
|---|---|---|
| Answer source | Pre-authored responses, decision tree | Your documents, databases, FAQs (at query time) |
| Out-of-scope queries | Fallback message, escalation, dead end | Answered if the information exists in your corpus |
| Content updates | Manual scenario edits | Re-index documents (automatable) |
| Time to ship | Fast, low upfront cost | Longer (ingestion, chunking, eval pipeline) |
| Operating cost | Low (hosting, near-zero LLM API calls) | Moderate to high (embeddings, LLM, vector store) |
| Hallucination risk | None (outputs are hand-written) | Present — requires faithfulness evaluation |
| Query coverage | Limited to anticipated scenarios | Handles arbitrary phrasing over indexed content |
3. Use a simple chatbot when
A rule-based or NLU-backed chatbot is the right call when:
- The question set is small, stable, and fully enumerable — order status, opening hours, a 15-item FAQ, appointment booking.
- Responses do not change often and can be authored once. The maintenance burden of hand-written answers is acceptable at this scale.
- You need deterministic, auditable outputs — compliance flows, regulated processes, anything where a hallucinated response creates legal or reputational risk.
- Budget and timeline are tight and you want a working first-level support layer without building an ingestion pipeline.
When simple is enough
Contact form, appointment booking, FAQ under 20 questions, routing to a human agent. In these cases, a rule-based chatbot (or a tiny NLU model) delivers the outcome without the complexity of RAG. Don't reach for retrieval if you don't need it.
4. Switch to RAG when
RAG becomes the right architecture when:
- Answers depend on a large, evolving document corpus — product manuals, contracts, SOPs, technical documentation, legal research, internal knowledge bases.
- User queries are open-ended and unpredictable in phrasing; you cannot enumerate scenarios in advance.
- You need responses to cite sources and stay grounded in your data — not in the LLM's parametric knowledge, which may be stale or domain-agnostic.
- Maintaining hundreds of hand-authored answers has become a maintenance bottleneck and a staleness risk.

Strong RAG use cases: e-commerce customer support (product catalog, return policies), industrial maintenance copilots (equipment manuals, maintenance procedures), internal knowledge assistants (HR policies, IT runbooks, engineering wikis), legal document search (contracts, case law, regulatory filings). In all of these, a rule-based chatbot hits its ceiling fast. If your domain involves multimodal documents (PDFs with tables, figures, scanned forms), also account for the multimodal extraction layer RAG requires in those cases.
Lesson learned
We deployed a RAG assistant for a medical software vendor's support team. Their documentation ran to several thousand pages of release notes, integration guides, and API references. A rule-based chatbot had been tried before and stalled at 60 pre-written Q&A pairs before the maintenance burden became unsustainable. The RAG system handled the same corpus automatically and reduced support ticket volume by 50% within three months of launch.
5. Hybrid patterns: chatbot + RAG
The most common production architecture is not either/or — it is a composition:
- Intent classifier at the front door. A lightweight model (or scripted logic) classifies the incoming query into structured intents (booking, complaint, billing, product question). Structured intents go to deterministic flows. Open-ended "information retrieval" intents go to the RAG layer.
- RAG behind the router. Once intent is known, RAG queries the appropriate knowledge base (product FAQ, technical docs, legal corpus) and generates a grounded answer. The retriever can be hybrid search with reranking for better precision.
This pattern keeps sensitive flows deterministic (payments, form submissions, escalations) while delivering rich, current answers on documented topics. It is also the natural starting point before you move to agentic RAG, where the retrieval decisions themselves are delegated to an agent.
Architecture tip
Start with the simplest possible router — even a keyword list or a small classifier. Add RAG only for the intents where open-ended retrieval is clearly needed. Expand the RAG scope as you measure quality. Trying to RAG everything on day one typically results in a system that is hard to evaluate and hard to debug.
6. The decision checklist
Four questions to pick the right architecture:
- Are the responses fully enumerable and stable? If yes, and phrasing is predictable: simple chatbot. If no: RAG or hybrid.
- Do answers require searching documents or databases? If yes: RAG (or hybrid with RAG behind the router).
- How often does the content change, and at what volume? High churn + large corpus: RAG. Rarely changes + short list: chatbot.
- Is source attribution or hallucination control required? If yes: RAG with faithfulness evaluation. A naive chatbot that just calls an LLM without retrieval does not give you this — see our notes on production RAG failure modes for what can go wrong even with retrieval in place.
7. Cost and complexity reality check
RAG is not universally better. It is better when the use case justifies the engineering investment. The honest cost breakdown:
Simple chatbot: Near-zero LLM API costs if you avoid an LLM backend entirely. Hosting is cheap. Maintenance cost is manual but predictable. Scales poorly with answer diversity.
RAG: Every query costs embedding + vector search + LLM generation. For a high-volume deployment, this adds up fast. Before you scale, model the cost: average query tokens, context window per request, output length, LLM pricing. At sufficient volume, you may be looking at a self-hosted RAG architecture to control unit economics. Also budget for evaluation infrastructure — a RAG system without a continuous eval pipeline is a system you cannot measure or safely improve. The fine-tuning vs RAG vs prompting tradeoff is worth reading if you are also considering baking knowledge into the model weights instead.
The economics flip toward RAG when: (a) query diversity exceeds what hand-authored answers can cover, (b) corpus size makes manual maintenance unsustainable, or (c) accuracy and source citation requirements are non-negotiable. When none of those apply, the simpler system wins.
8. Conclusion
RAG and a simple chatbot solve different problems. A chatbot automates defined flows cheaply and predictably. RAG unlocks open-ended question answering grounded in your data, at a higher engineering and operational cost. The right choice follows directly from your query distribution, corpus characteristics, content update frequency, and accuracy requirements.
For most teams: start with the simplest thing that could work, measure where it fails, and add RAG (or a hybrid layer) when the failure modes of the rule-based system become the bottleneck. If you want to understand how model choice affects your RAG backend, see our comparison of Mistral vs OpenAI vs Anthropic. And if you need structured, typed outputs from your RAG pipeline, structured outputs in production covers the patterns that work.
Talk to an engineer
Not sure whether your use case needs RAG? We'll tell you in one call.
FAQ: RAG vs simple chatbot
Further reading
- RAG: A Technical Guide — How RAG works end to end: embedding, chunking, vector stores, and where it breaks.
- Production RAG: 5 Failure Modes — The recurring failure patterns we see when RAG ships to production and how to fix them.
- Agentic RAG — When you hand retrieval decisions to an agent. Covers multi-step retrieval, planning, and when it's worth the complexity.
- Hybrid Search and Reranking — Combining dense and sparse retrieval to improve precision before the LLM ever sees context.
- Fine-tuning vs RAG vs Prompting — How to decide whether to retrieve, tune the model, or just prompt better.
- Self-hosted RAG Architecture — When the unit economics of cloud RAG push you toward running your own stack.
- Vector Database Comparison — Choosing the right vector store for your RAG system: Pinecone, Weaviate, Qdrant, pgvector, and more.
- Embedding Models Guide 2026 — Which embedding model to use, benchmarked on real retrieval tasks.
- RAG systems service — End-to-end RAG deployment including ingestion, eval infrastructure, and observability.
- AI audit — Structured review of your AI use case to recommend the right architecture before you build.

