Le 7 avril 2026, Anthropic a dévoilé Claude Mythos Preview. Les chiffres sont sans appel : 93,9 % sur SWE-bench Verified, 94,6 % sur GPQA Diamond, 82 % sur Terminal-Bench. Ce modèle surpasse tous les records existants en code, en raisonnement et en autonomie.
Mais il y a un twist : vous n'y aurez pas accès. Pas tout de suite, en tout cas. Anthropic a fait le choix inédit de ne pas rendre ce modèle public, parce que ses capacités en cybersécurité sont jugées trop puissantes pour être mises dans toutes les mains sans garde-fous.
Voici ce que ce modèle change, pourquoi Anthropic le garde sous clé, et ce que ça signifie pour la suite.
Un modèle généraliste, pas un outil spécialisé
Premier point important : Claude Mythos Preview n'a pas été entraîné spécifiquement pour la cybersécurité ou pour le code. C'est un modèle généraliste, comme les versions de Claude que vous connaissez peut-être déjà. Il sait rédiger, analyser, résumer, raisonner, coder.
Ce qui le distingue, c'est que ses capacités générales ont franchi un seuil où il devient exceptionnellement bon dans des domaines qui demandaient auparavant une expertise humaine de très haut niveau. En clair : en devenant meilleur en raisonnement et en code de manière générale, il est devenu redoutable pour trouver des failles de sécurité, sans qu'on lui ait appris spécifiquement à le faire.
Le point clé
Mythos Preview n'est pas un outil de hacking. C'est un modèle d'IA généraliste qui se trouve être si bon en raisonnement et en code que ses capacités en sécurité informatique en sont une conséquence naturelle.
Les performances en code : un bond spectaculaire
Le code est le domaine où le progrès est le plus visible. Les benchmarks SWE-bench testent la capacité d'un modèle à corriger de vrais bugs dans de vrais projets open source. Ce ne sont pas des exercices académiques : ce sont des issues GitHub réelles, avec du code réel et des tests réels.
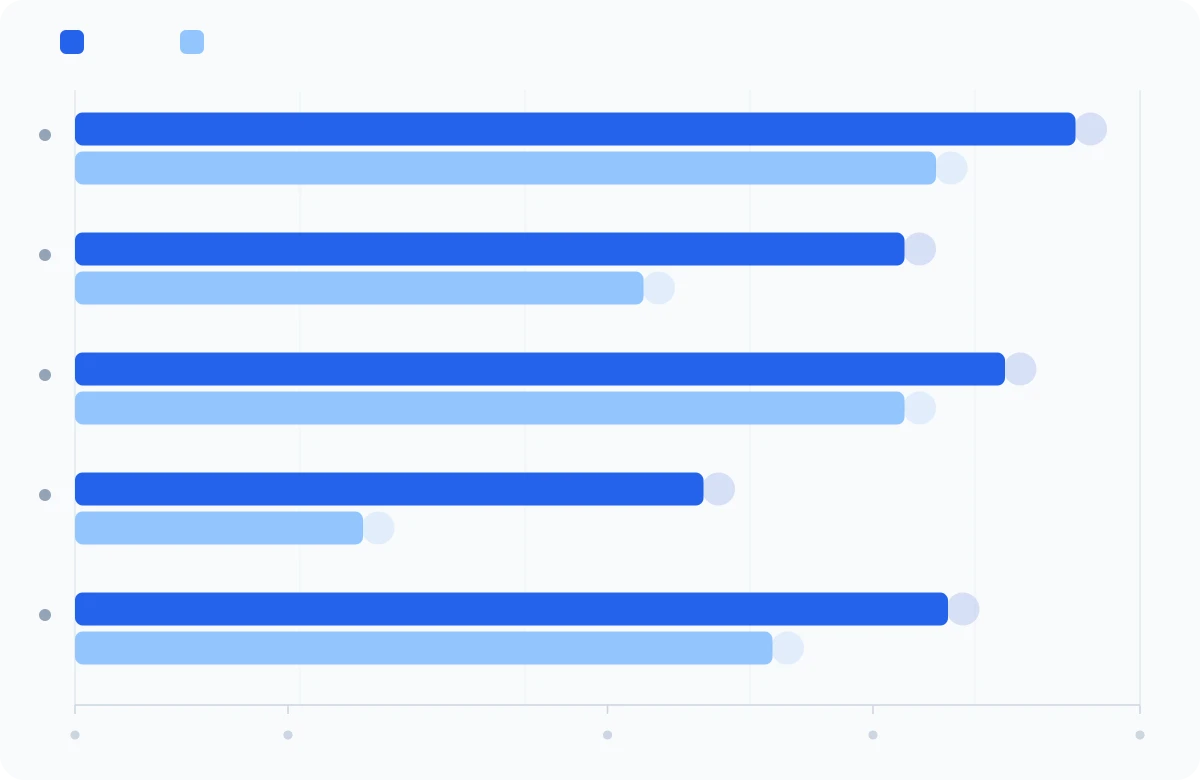
| Benchmark | Mythos Preview | Opus 4.6 | Progression |
|---|---|---|---|
| SWE-bench Verified | 93,9 % | 80,8 % | +13,1 pts |
| SWE-bench Pro | 77,8 % | 53,4 % | +24,4 pts |
| SWE-bench Multilingual | 87,3 % | 77,8 % | +9,5 pts |
| SWE-bench Multimodal | 59,0 % | 27,1 % | +31,9 pts |
| Terminal-Bench 2.0 | 82,0 % | 65,4 % | +16,6 pts |
Quelques repères pour mettre ces chiffres en contexte :
- SWE-bench Verified (93,9 %) : sur 100 vrais bugs issus de projets open source, Mythos en corrige correctement 94. Il y a un an, les meilleurs modèles plafonnaient à 50 %.
- SWE-bench Pro (+24 pts) : ce sont les bugs les plus complexes. Passer de 53 % à 78 % signifie que le modèle résout désormais des problèmes qui demandaient auparavant un développeur senior expérimenté.
- SWE-bench Multimodal (+32 pts) : le modèle peut maintenant comprendre des screenshots, des maquettes et des captures d'écran pour corriger des bugs visuels. La progression est la plus forte de tous les benchmarks.
- Terminal-Bench 2.0 (82 %) : ce benchmark teste la capacité du modèle à travailler de manière autonome dans un terminal, comme un développeur le ferait. Le score monte même à 92 % quand on lui laisse plus de temps.
Les performances en raisonnement : au niveau des meilleurs experts
Le raisonnement est l'autre axe de progrès majeur. GPQA Diamond et Humanity's Last Exam sont des benchmarks conçus pour tester les limites de la compréhension et du raisonnement, avec des questions qui piègent régulièrement des experts de domaine.
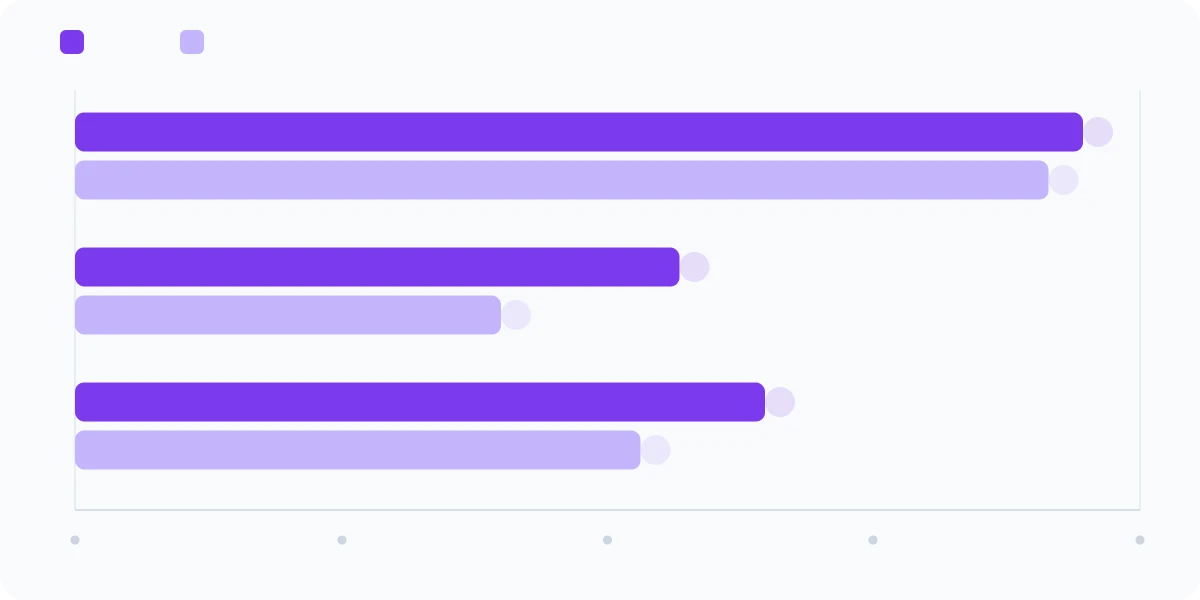
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| GPQA Diamond | 94,6 % | 91,3 % |
| Humanity's Last Exam (sans outils) | 56,8 % | 40,0 % |
| Humanity's Last Exam (avec outils) | 64,7 % | 53,1 % |
GPQA Diamond contient des questions de niveau doctorat en physique, biologie et chimie. 94,6 % signifie que Mythos Preview rivalise avec les meilleurs experts humains dans ces domaines. L'écart avec Opus 4.6 peut sembler faible (3 points), mais à ce niveau de difficulté, chaque point gagné représente un saut considérable.
Humanity's Last Exam est le benchmark le plus difficile qui existe : il rassemble des questions créées par des experts dans tous les domaines, conçues pour être les plus difficiles possible. Passer de 40 % à 57 % sans outils, c'est considérable.
Capacités agentiques : recherche et manipulation d'ordinateur
Les benchmarks "agentiques" mesurent la capacité du modèle à agir de manière autonome : naviguer sur le web, utiliser un ordinateur, enchaîner des actions complexes sans intervention humaine.
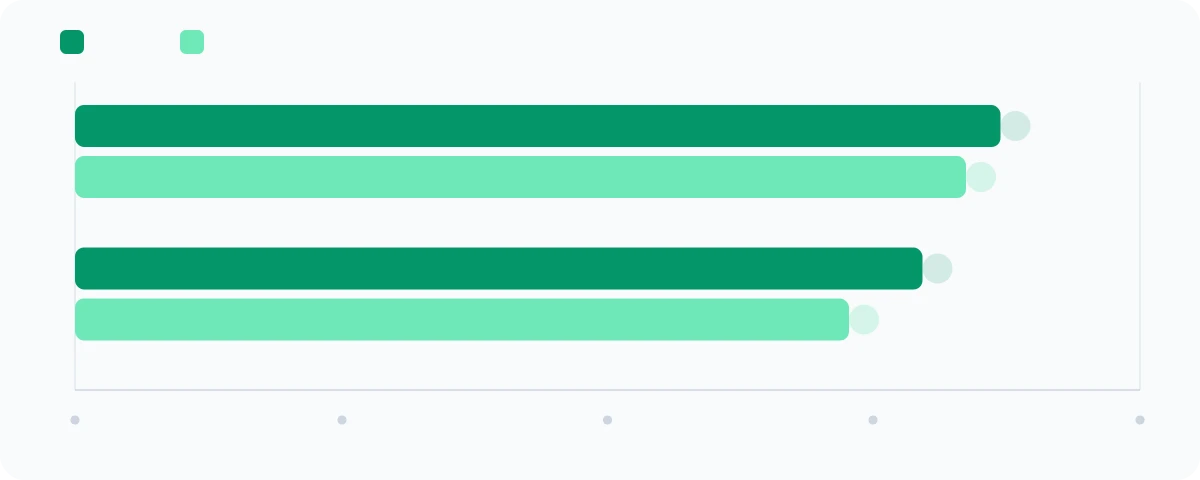
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| BrowseComp (recherche web) | 86,9 % | 83,7 % |
| OSWorld-Verified (utilisation d'un OS) | 79,6 % | 72,7 % |
Ce qui est remarquable ici, c'est l'efficacité. Sur BrowseComp, Mythos Preview obtient un meilleur score en utilisant 5 fois moins de tokens que Opus 4.6. Il ne se contente pas d'être meilleur, il est aussi plus rapide et plus économe.
OSWorld-Verified teste si le modèle peut accomplir des tâches réelles sur un vrai système d'exploitation (ouvrir des applications, modifier des fichiers, naviguer dans des menus). 79,6 % signifie qu'il réussit presque 4 tâches sur 5 de manière totalement autonome.
Pourquoi ce modèle n'est pas accessible au public
C'est la décision la plus inhabituelle de cette annonce. Habituellement, quand un labo d'IA crée un modèle record, il le commercialise le plus vite possible. Anthropic fait l'inverse.
La raison est directement liée aux capacités du modèle en cybersécurité. En devenant aussi bon en code et en raisonnement, Mythos Preview est devenu capable de :
- Trouver des failles de sécurité inconnues dans les logiciels les plus utilisés au monde
- Écrire des exploits fonctionnels pour démontrer (ou utiliser) ces failles
- Enchaîner plusieurs vulnérabilités pour construire des attaques sophistiquées
- Faire tout cela de manière largement autonome, l'humain intervenant surtout pour valider les résultats
Face à ce constat, Anthropic a choisi de limiter l'accès au modèle aux partenaires de son initiative Project Glasswing (Google, Microsoft, AWS, Apple, Cisco, CrowdStrike, etc.) pour un usage défensif. Concrètement, le modèle détecte et documente les failles, et ce sont les équipes de sécurité de ces partenaires qui vérifient chaque résultat avant d'agir.
La stratégie d'Anthropic
L'idée est de laisser les défenseurs utiliser ces capacités pour corriger les failles avant que des modèles équivalents ne soient disponibles ailleurs. Anthropic travaille en parallèle sur des protections qui seront intégrées dans un prochain modèle Claude Opus destiné au public.
Ce que ça nous apprend sur la trajectoire de l'IA
Au-delà des chiffres, Mythos Preview confirme plusieurs tendances de fond.
La courbe de progression ne ralentit pas
Il y a eu beaucoup de discussions ces derniers mois sur un possible "plateau" des modèles de langage. Mythos Preview met fin à ce débat. Le bond entre Opus 4.6 et Mythos Preview est l'un des plus grands jamais observés entre deux générations de modèles d'un même labo.
Sur SWE-bench Pro, on passe de 53 % à 78 %. Sur SWE-bench Multimodal, de 27 % à 59 %. Ce ne sont pas des améliorations marginales.
L'autonomie change la nature des capacités
Ce qui rend Mythos Preview qualitativement différent, ce n'est pas juste qu'il "sait plus de choses". C'est qu'il peut agir seul sur des tâches complexes et longues. Trouver une faille dans OpenBSD demande de lire des milliers de lignes de code, formuler des hypothèses, les tester, itérer. Mythos déroule tout ce processus seul, à charge ensuite pour les experts de confirmer la faille avant toute action.
Cette autonomie transforme un modèle qui "aide un humain" en un modèle qui "fait le travail d'un expert". C'est un changement qualitatif, pas juste quantitatif.
Les capacités dangereuses émergent naturellement
Personne chez Anthropic n'a entraîné Mythos à trouver des failles de sécurité. Ces capacités sont apparues comme une conséquence naturelle de l'amélioration des capacités générales en code et en raisonnement. C'est un signal important : à mesure que les modèles deviennent plus capables, certaines capacités sensibles émergent qu'on le veuille ou non.
Cela pose une question fondamentale pour l'ensemble de l'industrie de l'IA. Si n'importe quel modèle suffisamment bon en code devient automatiquement un outil de cybersécurité offensif, comment gérer la diffusion de ces modèles ?
Ce que ça signifie concrètement pour vous
Si vous utilisez déjà Claude dans votre entreprise
Bonne nouvelle : les capacités de Mythos Preview indiquent la direction des prochaines versions de Claude. Les modèles que vous utilisez aujourd'hui (Opus 4.6, Sonnet 4.6) vont continuer à s'améliorer. Les gains en code, en raisonnement et en autonomie se retrouveront dans les versions futures accessibles au public, une fois les protections en place.
Si vous hésitez encore à intégrer l'IA
Ce type d'annonce devrait accélérer votre réflexion. Le rythme de progression est tel que l'écart entre les entreprises qui utilisent l'IA et celles qui ne le font pas va se creuser de manière accélérée. Les modèles actuels sont déjà très capables. Les prochains le seront beaucoup plus.
Pour la sécurité de vos systèmes
Si Mythos Preview peut trouver des failles dans les logiciels les plus sécurisés du monde, il peut en trouver dans les vôtres aussi. Les mises à jour de sécurité, la réduction de la dette technique et l'utilisation de l'IA pour auditer votre code ne sont plus des luxes, ce sont des nécessités.
L'IA avance vite
Vous voulez comprendre ce que ces progrès changent pour votre entreprise ?
Ce qu'il faut retenir
Claude Mythos Preview marque un moment charnière dans le développement de l'IA :
- 93,9 % sur SWE-bench Verified : le modèle corrige presque tous les vrais bugs qu'on lui soumet
- +24 points sur SWE-bench Pro par rapport à Opus 4.6 : le bond le plus important entre deux générations
- 94,6 % sur GPQA Diamond : un niveau de raisonnement qui rivalise avec les meilleurs experts humains
- Des capacités en cybersécurité si puissantes qu'Anthropic refuse de rendre le modèle public
- Un signal clair : la progression de l'IA ne ralentit pas, elle accélère
Pour les entreprises, le message est simple. Les outils d'IA disponibles aujourd'hui sont déjà très performants. Ceux de demain le seront considérablement plus. Se préparer maintenant, c'est se donner les moyens de tirer parti de cette accélération plutôt que de la subir.
Mise à jour : le 9 juin 2026, Anthropic a franchi l'étape annoncée ici. Les capacités de classe Mythos sont désormais accessibles au grand public via Claude Fable 5, la version rendue sûre par des garde-fous automatiques, tandis que Claude Mythos 5 reste réservé aux cyberdéfenseurs. Notre décryptage détaille ce que ce lancement change concrètement pour une PME : accès, prix, sécurité et politique de données.
Pour aller plus loin
- Claude Fable 5 et Mythos 5 : la sortie grand public des capacités de classe Mythos, avec ses garde-fous, son prix et sa nouvelle politique de données.
- Claude Opus 4.8 pour l'entreprise : la version disponible aujourd'hui, déjà proche de Mythos sur l'alignement.
- Une IA plus honnête en entreprise : ce que les progrès d'alignement changent pour vos projets en production.
- Project Glasswing : la coalition lancée par Anthropic pour sécuriser les logiciels critiques grâce à Mythos Preview
- Audit IA : évaluez comment l'IA peut transformer vos processus
- Agents IA vs chatbots : comprendre les différences et choisir le bon outil pour votre entreprise
- Assistant IA interne : déployer un assistant IA sécurisé sur vos données d'entreprise
- Guide automatisation IA pour PME : automatiser vos processus métier avec l'IA
- RAG vs fine-tuning : choisir la bonne architecture IA pour votre cas d'usage
- Automatisation de processus : nos solutions d'automatisation sur mesure

